This article is transferred from: Shaanxi Daily
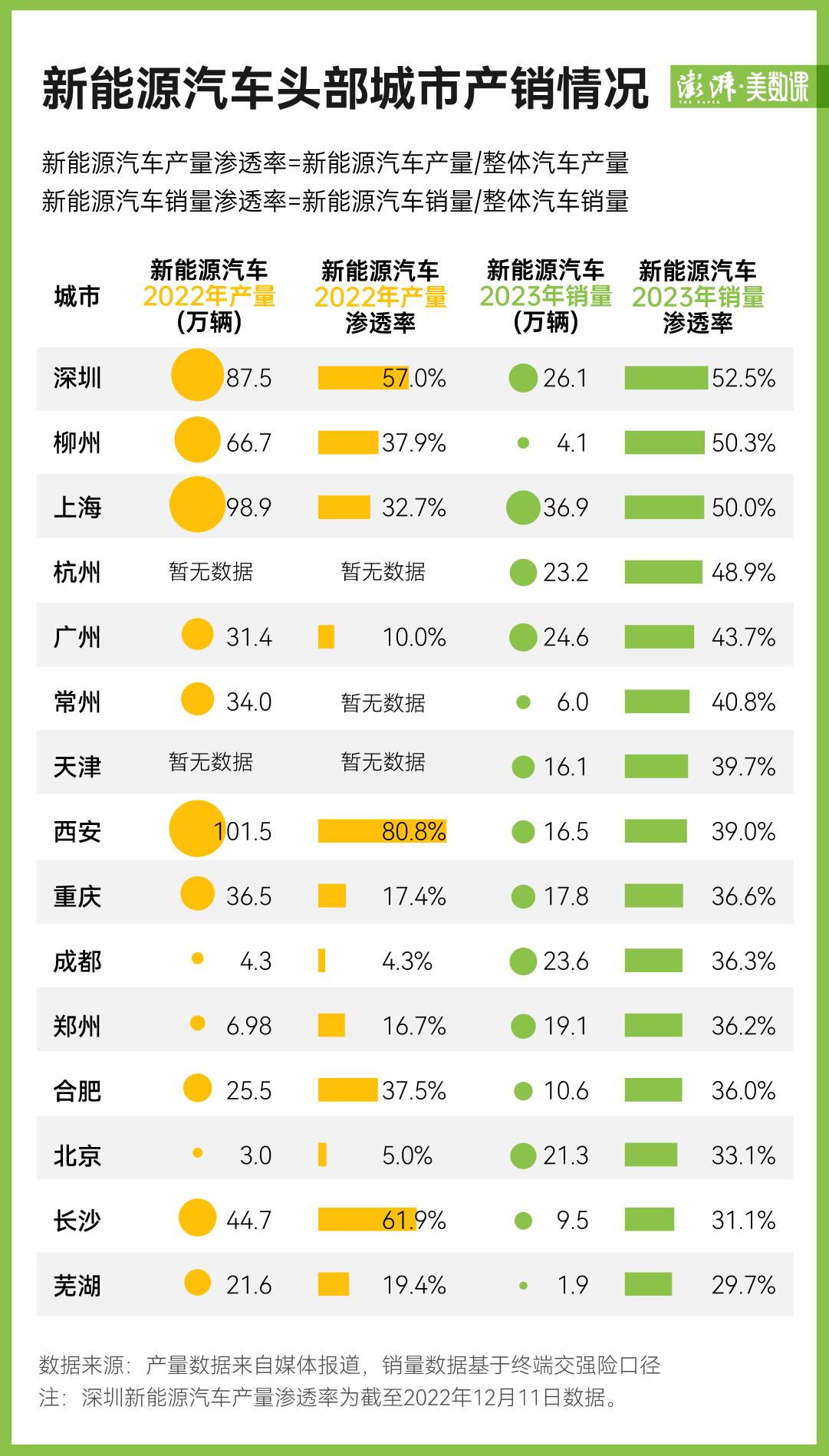
Shaanxi, a major fruit province, has a good report card: the planting area and output of apples and kiwifruits rank first in the world, the cherry planting area ranks second in the country, and the grape planting area ranks third in the country.
Appropriate temperature and humidity, sufficient light and precipitation give Shaanxi fruit a unique flavor and taste. However, Shaanxi, where the planting area and output of fruits rank first in the country, is rich in fruit types, but most of the fresh fruits are harvested in summer and autumn. In winter and spring, the bulk fruits are mainly stored in cold storage, and the local seasonal fruits are not enough to compete with other provinces, which leads to the occupation of Shaanxi fruit market in winter and spring by a large number of foreign seasonal fruits.
How can we stay in the "C position" of the fruit market stage? In the past few days, reporters have visited the market and visited the producing areas, trying to find the "password" for Shaanxi to seize the highland of the fruit market.
1 spring fruit market rarely sees local goods.
On April 12, people came and went in the fruit sales area of Boxma Xiansheng on Jiefang Road in Xi ‘an. The shelves are filled with rows of fruits, such as red strawberries, orange oranges, yellow bananas and green avocados, which are dazzling and attractive. A closer look shows that there are not many local fruit varieties in Shaanxi.
"From February to April, local fruits in Shaanxi only accounted for about 10% of the total sales of fresh fruits in Boxma." Zhang Weibo, fruit purchasing manager of Xi ‘an Box Horse Network Technology Co., Ltd. said.
Zhang Weibo told reporters that the spring fruits sold by Boxma Xiansheng are mainly produced in Hainan, Yunnan, Guangxi, Sichuan, Chongqing and other places. The varieties mainly include mango, litchi, honeydew melon, banana, lotus fog, lemon and small green orange in Hainan, Chu orange, honey pomelo, wogan, grape, watermelon and blueberry in Yunnan, and loquat and navel orange in Sichuan and Chongqing. Shaanxi local fruits mainly include Luochuan Red Fuji Apple, Ruixue Apple, Shaanxi Cuixiang Kiwi, Yanliang Melon, strawberries, blueberries and other fruits. On the whole, among the spring fruits sold by Boxma Xiansheng, the most popular ones are early-maturing cherries, blueberries, orange pomelo, pineapples, honeydew melons and other varieties.
Zhang Weibo said that with the improvement of living standards in recent years, consumers have higher and higher requirements for the quality of fruits, and they have put forward higher requirements for the appearance, taste, nutrition and safety of fruits. Fruits in the province, outside the province and even abroad are seizing the market, and the competition is becoming more intense. In order to seize a place, fruits must be of good quality and distinctive.
As a typical representative of the new retail industry, Boxma Xiansheng can see the huge challenges faced by local fruits in Shaanxi from its fruit sales. Then, in the fruit wholesale market, will the sales of local fruits in Shaanxi be different?
On April 8, the reporter went to Suzaku Agricultural Products Wholesale Market in Chang ‘an District of Xi ‘an to find out. In a shop called Suzaku Xingmao Fruit Shop, there are all kinds of fruits. The owner, Ms. Liu, told the reporter that after the Spring Festival, there was a gap in local fruits in Shaanxi, and the main products on sale were apples, kiwis and other cold storage stocks. At present, among all the fruit varieties in the store, citrus fruits and apples sell a lot, among which Luochuan Red Fuji is the main apple, and Shaanxi apples are still very competitive.
Zhang Jian, deputy general manager of Suzaku Agricultural Products Wholesale Market, told the reporter that Suzaku Agricultural Products Wholesale Market is the distribution center of agricultural products retail and wholesale in the south of Xi ‘an. At present, affected by the epidemic, the market sells 30 to 40 tons of fruits every day, mainly apples, bananas, rakes, watermelons, strawberries and so on. Among them, the local fruits in Shaanxi mainly include apples, pears and strawberries.
In this market, the daily sales volume of apples is about 10 tons, mainly from Luochuan, and some from Gansu, Tongchuan, Baoji and other places. The price of "90 fruits" (apples with a diameter of 90 mm) ranges from 8 yuan to 9 yuan per kilogram. Mid-April is the peak period of strawberry sales, and about 5 tons can be sold every day. Strawberries are mainly produced in Huyi District of Xi ‘an, zhouzhi county, Lantian County, etc. According to different quality, the price ranges from 10 yuan to 16 yuan per kilogram. In addition, the price of Pucheng crisp pear ranges from 6 yuan to 6.5 yuan per kilogram. Kiwifruit stocks in zhouzhi county and Meixian are small, and they will be sold out soon after the year. This year’s cherry was listed a little later than in previous years, but the cherry output showed an upward trend year after year, becoming a major force for Shaanxi fruit to seize the market.
2 Chengcheng Cherry Breakthrough Against the Trend
Before the Spring Festival this year, merchants from other provinces booked all the cherries produced by Wupo Ecological Agriculture Development Co., Ltd., Wujiapo Village, Siqian Town, Chengcheng County, at the price of one kilogram of 800 yuan. This price, like a bomb, exploded among cherry farmers in Chengcheng County, making people marvel at the power of modern agricultural science and technology.
The company has built 12 intelligent greenhouses and planted cherry trees called "a stick". Through intelligent management and agricultural science and technology, the ripening time of cherries was advanced to the Spring Festival, thus selling them at a good price.
Qi Wugang, the manager of the company, is extremely happy. He plans to build at least 30 smart greenhouses with floor heating and air conditioning this year.
In recent years, the domestic big cherry has quickly become popular and become a "upstart" of fruit. Chengcheng County is located in the eastern part of Weibei Plateau, with thick land and large temperature difference, and is recognized as a high-quality cherry producing area in China. Chengcheng County, based on the county resource endowment, put forward the goal of "the first cherry county in China".
In 2018, Chengcheng County established the first national-level cherry experimental station in the province, and continued to promote variety improvement, planting experiments and technical training, which provided scientific and technological backing for the development of cherry industry. With the support of new technology, some fruit farmers tried to develop cherries in cold shed, which advanced the maturity of cherries by more than 20 days. These 20 days have increased the price of cherries by at least 50%. The fruit farmers who tasted the sweetness went on to develop cherries in greenhouses. Compared with the cold shed, although the investment in the greenhouse is much larger, the harvest time of the cherries produced is more than one month ahead of schedule, and the market time just coincides with the off-season of spring fruits, and the price is at least 10 times more expensive than that of ordinary cherries.
In order to further advance the time of cherry market and seize the Spring Festival market, Chengcheng County introduced a dwarf close planting mode to plant a "stick" cherry tree.
The tree shape of a "stick" cherry tree is very different from the traditional cherry tree. It has no crown and looks like a stick, which directly blooms and bears fruit on the "stick". Its characteristic is that it can be planted densely, at least 1000 plants can be planted per mu of land, and it can also be potted, which is convenient to move.
It is understood that compared with ordinary cherry trees, the planting management of "one stick" is relatively complicated and cumbersome. Plant it in a pot and cultivate it until August, then move the pot into a cold storage for forced dormancy. When winter comes, move it back to the greenhouse for "awakening" and let it grow leaves, blossom and bear fruit in an intelligent temperature-controlled environment. In this way, the cherries produced by it can just be mature and listed during the Spring Festival, grab the word "early" and sell at a good price. Fruit farmers in Chengcheng County affectionately call this potted cherry tree cultivated by hibernation temperature control technology "a stick".
With the planting and promotion of "one stick", Chengcheng cherry has changed from the initial harvest period to four harvest periods. At present, the planting area of cherries in Chengcheng County has reached 100,000 mu, with an annual output of 50,000 tons and an annual output value exceeding 1 billion yuan. Cherry industry has become a dominant industry in Chengcheng County to promote rural revitalization and help people increase their income and get rich.
The planting of "a stick" in Chengcheng is a bold attempt of Shaanxi fruit farmers, which has advanced the time of cherry market to around the Spring Festival. This means that even in the cold winter, Shaanxi has a real "seasonal" fruit.
3. Facility agriculture makes fruits appear on the market at the wrong peak
As early as the end of March, the cherry was not mature, and Fan Jianwu, secretary of the Party branch and director of the village committee of Fanjiachuan Village, Jiaodao Town, Chengcheng County, began to get busy. He was not only busy shooting videos and promoting cherries on Tik Tok, but also contacted old customers on WeChat to reserve cherries for them in advance.
Fanjiachuan Village is rich in fruits and has the reputation of "Huaguoshan". In spring, agricultural products such as cherry, golden birthday apricot and melon in greenhouse bring the villagers the joy of harvest. It is understood that there are more than 200 greenhouses in Fanjiachuan village, mainly planting peaches, apricots, cherries, winter dates and other fruits, which can increase the income of local people by more than 10 million yuan every year on average.
"At present, our village has planted 500 mu of cherries, including more than 100 mu of greenhouses, which can advance the time to market of cherries by at least half a month, laying a good foundation for seizing the market." Fan Jianwu told reporters that this year is a bumper harvest year. The quality and yield of cherry in greenhouse have been greatly improved compared with the previous year. The average yield per mu has reached more than 1,000 kilograms, and merchants are rushing to order, not worrying about selling at all.
The greenhouse gave the fruit farmers in Fanjiachuan village the confidence to get rich. With the help of facility agriculture, in spring, local fruits such as cherries, strawberries and tomatoes in Shaanxi are listed on the market, which gives them the capital to compete for the spring fruit market.
The reporter noticed that in many fruit shops in Xi ‘an, cherry tomatoes accounted for a large proportion and became the "master Hua Dan" in the spring fruit market.
In Suzaku Agricultural Products Wholesale Market, there are many fruit merchants selling fruit tomatoes, the colors of which are red, yellow and black and red, which are really attractive.
"Local fruit tomatoes also actively seize the spring fruit market. Provence tomatoes and cherry tomatoes from Yunyang Town, Jingyang County are the best sellers. At present, they can sell 4,000 kilograms a day. The wholesale price is about 9 yuan per kilogram, and the retail price ranges from 10 yuan to 12 yuan per kilogram. " Zhang Jian said.
On the evening of April 22, Wang Bo, chairman of Yunlong Vegetable Professional Cooperative in Jingyang County, was still processing commodity orders. "Because our fruit tomatoes are of good quality and popular with consumers, we don’t worry about selling them. Before fruit tomatoes are listed, many old customers place orders on WeChat. " Wang Bo told reporters that the cooperative has always carefully built fruit tomatoes as fist products. Fruit tomatoes are not only diverse in variety, excellent in taste, but also green and safe, and are favored by consumers.
It is understood that Yunlong Vegetable Professional Cooperative in Jingyang County has 30 facilities and greenhouses. Among them, the red cherry tomatoes are pink Beibei, Gege, Busan 88 and other varieties, the yellow cherry tomatoes are first love 3, Huang Luoman and other varieties, and the fruit tomatoes are Provence, delicious 610, fruit strawberry, tin and other varieties. The price of red cherry tomatoes is about 10 yuan per kilogram, the price of yellow cherry tomatoes is about 14 yuan per kilogram, and the purchase price of fruits, strawberries and tomatoes is about 14 yuan per kilogram. At present, cooperatives sell fruit tomatoes through e-commerce platforms and WeChat channels, with an average daily sales of about 10,000 kilograms and sales of more than 100,000 yuan.
In recent years, Jingyang County has made every effort to build "the first tomato county in Shaanxi". Under the guidance of government departments, many local tomato planting professional cooperatives have been constantly improving varieties, improving the sugar content and taste of tomatoes by changing sheds, water and soil, and improving the popularity and value of Jingyang tomatoes by extending sales time, listing at the wrong peak and ensuring supply. Every year from the beginning of February to the end of April is the decisive period of local water supply in Shaanxi, and fruit tomatoes are just on the market and can be sold continuously until July, which provides a good opportunity for fruit tomatoes to seize the market.
The adjustment of industrial structure makes Shaanxi bear fruit in four seasons.
Affected by natural conditions, there are not many kinds of fruits produced in Shaanxi in spring, and there are few high-end fruits and famous brands. In order to seize the market, Shaanxi fruit industry must work hard to improve quality and efficiency to meet consumers’ demand for fruits with good quality and high value. Only by planting high-quality fruits can fruit farmers win the market and increase their income.
The reporter learned from the Fruit Industry Department of the Provincial Department of Agriculture and Rural Affairs that in recent years, relying on the construction of "three products and one standard" in the fruit industry, our province has accelerated its efforts to seize the fruit market.
Shaanxi relies on varieties to stand on the market, actively conforms to the trend of diversification of market demand and consumption concepts, insists on the combination of introduction and breeding, accelerates the promotion of new and excellent fruit varieties, optimizes the variety structure, improves the proportion of early, middle and late ripening, promotes the differentiated development of fruit varieties with different colors and tastes, and firmly grasps the market initiative.
Shaanxi wins the market by quality. By establishing high-quality and high-efficiency orchards, integrating and popularizing green, high-quality and high-efficiency fruit production technologies, expanding the coverage area of green manure planting and organic fertilizer, the commodity rate of fruits is improved. Build a post-harvest processing center for fruits, promote the unified purchase and classification of producing areas and pre-cooling after harvest, extend the shelf life and establish a good market reputation.
Shaanxi relies on brands to explore the market, accelerate the construction of a three-dimensional brand system, and promote the standardized development of regional public brands, corporate brands and product brands; Establish Shaanxi fruit industry brand alliance to form a joint force for brand development; Strengthen brand promotion, promote the development of fruit e-commerce and continuously increase market share.
Shaanxi relies on standardization to consolidate the market, give full play to the leading role of leading enterprises, strengthen the certification of green fruits and the establishment of organic fruit production bases, and establish a standardized system for garden building, cultivation, management, storage, packaging, transportation and sales of high-quality fruits that adapt to the modern market.
The scale of production has gone up, and the promotion should also keep up. On May 18th, a special summer fruit "beauty contest" was held in Boxma Xiansheng. The Provincial Fruit Industry Center, together with representatives of nearly 30 fruit enterprises in the province, docked with Box Horse to help the special fruits in the province enter the fresh supply system of Box Horse. "We have initially reached cooperation intentions with seven or eight fruit companies." Ze Ting, general manager of Boxma Xiansheng Xi ‘an, said that since Boxma Xiansheng entered Xi ‘an, many Shaanxi fruits have gone to the whole country through the supply chain of Boxma Xiansheng.
On the same day, the third China Chengcheng Cherry Cloud Marketing Season and Shaanxi Fruit Network Characteristic Season Cherry Season opened. The holding of these activities has promoted the docking of production and marketing and expanded the sales circle of Shaanxi fruits.
Through a series of "combination boxing", in the main season of non-Shaanxi local fruits, Shaanxi is struggling to compete for the highland of fruit market by improving varieties, listing at the wrong peak, building brands and promoting sales, so that people can eat Shaanxi local fruits all year round, and truly realize that a big fruit province has fruits in all seasons.